CS 241 Project 5: Autocomplete
- Getting started
- Part A: Quicksort
- Part B: HashtableMap
- Part C: Reading the file
- Part D: Writing the autocorrector
- Part E: Celebrate
- Testing your code
- At the end of the project
- Submitting your code
- Hints and tips
Reminder: Everything in this project must be your own work. If you include any code that was not invented by you, you must give a citation for it.
Getting started
- Download the starter code 💾 here.
- Make a new Intellij project. Then copy the contents of this
srcfolder exactly into thesrcfolder in the new project. Do not “nest” thesrcfolders inside each other!
Autocomplete is pervasive in modern applications. As the user types, the program predicts the complete query (typically a word or phrase) that the user intends to type. Autocomplete is most effective when there are a limited number of likely queries. For example, the Internet Movie Database uses it to display the names of movies as the user types; search engines use it to display suggestions as the user enters web search queries; cell phones use it to speed up text input.
In these examples, the application predicts how likely it is that the user is typing each query and presents to the user a list of the top-matching queries, in descending order of likelihood. These likelihoods are determined by historical data, such as box office revenue for movies, frequencies of search queries from other Google users, or the typing history of a cell phone user. For the purposes of this assignment, you will have access to a corpus of English text from which you will deduce how likely it is for certain words to be autocompleted in various ways.
The performance of autocomplete functionality is critical in many systems. For example, consider a search engine (such as Google) which runs an autocomplete application on a server farm. According to one study, the application has only about 50 milliseconds to return a list of suggestions for it to be useful to the user. Moreover, in principle, it must perform this computation for every keystroke typed into the search bar and for every user!
In this assignment, you will implement autocomplete in four parts.
Part A: Quicksort
In this part, you will implement the quicksort algorithm and write some tests to make sure it is correct. For this part, you will work on the files Quicksort.java and QuicksortTester.java.
The code you will write will be based on the quicksort code from class, so you should base your code off of that. The only difference is that your code will use ArrayLists rather than plain arrays, and we will use a Comparator to let us sort things in different ways.
What is a Comparator?
A Comparator is a Java class that implements the Comparator interface. The Comparator interface has only one method that must be implemented, which is compare. The compare function in a Comparator is almost exactly like the compareTo function in a Comparable object. Here’s the difference:
- The
Comparableinterface is implemented in the objects themselves that will eventually be compared (or sorted). For instance, Integers and Strings are comparable. Every class that implementsComparablehas acompareTomethod that takes a single argument of that class, and callinga.compareTo(b)compares objectsaandb. The
Comparatorinterface is implemented in a separate class from the objects being sorted. Typically it is used to introduce some sort of alternate ordering method on objects that are already comparable, or to introduce an ordering on objects that do not have one built-in throughComparable. Every class that implementsComparatorhas acomparemethod that takes two arguments of the class that will be compared, and callingcompare(a, b)compares objectsaandb.- Both functions (
compareToandcompare) must return a negative number (often -1) if the first object (a) is “less than” the second (b), a positive number (often +1) if the first object is “greater than” the second, and zero if they are “equal,” where “equal” in this case means any two objects where the order shouldn’t matter.
Writing Part A
In
Quicksort.java, fill in thepartition()function. It mirrors thepartition()function from the quicksort handout discussed in class. The only differences are that it uses ArrayLists instead of plain arrays, and it uses aComparatorobject passed in as an argument, so every time the code from class compares items from the array with<,>, or==, you should use thecomparefunction on the comparator instead:REGULAR WAY WITH COMPARATOR ------------------------------------ if (a < b) if (compare(a, b) < 0) if (a > b) if (compare(a, b) > 0) if (a <= b) if (compare(a, b) <= 0) if (a >= b) if (compare(a, b) >= 0) if (a == b) if (compare(a, b) == 0)To adapt the code to ArrayLists, change every array access in the original code (that uses square brackets) to either use
.get(index)or.set(index, value). In other words, a line likevalue = array[x]would becomevalue = array.get(x)and a line likearray[x] = valuewould becomearray.set(x, value).- When you think you’re done with
partition(), try runningQuicksortTester. You should be able to sort numbers and individual letters forwards and backwards now. You will also notice the last case uses a Comparator at the end of the file calledIgnoreCaseComparator. Take note of this comparator, as you will be writing your own later.
✅✅✅ Compare against sample output.
Part B: HashtableMap
In this part, you will implement a Map based on a hash table (in the last project, you implemented a Map based on a BST). For this part, you will work on the files HashtableMap.java and HashtableMapTester.java.
Getting acquainted with HashtableMap
- A HashtableMap implements a map based on a hashtable. The hash table uses chaining. The table is based on this variable:
ArrayList<LinkedList<KVPair<K, V>>> table.- This is an ArrayList that contains linked lists. Each linked list contains a sequence of KVPairs (key-value pairs). The KVPair class is defined at the end of the file.
- This looks like a complicated definition, but if you read it from left to right, you should be able to parse out the meaning. KVPairs (of keys and values) inside of a LinkedList, inside of an ArrayList.
- Java objects always have a
hashCodefunction built in. Often when declaring your own objects, you override this function. What this means is that you don’t have to worry about writing hash code functions inside this class. - Take a look at the constructor for the class. Notice how it takes an
initialSizeparameter. This allows the user to set the size of the hashtable. This is very unusual in practice — normally the hash table size is controlled by the programmer. However, to allow us to play with the size of the table, we will allow it to be controlled by this parameter.
Writing Part B
I suggest the following steps to write this class.
- Write the
put()function, which accepts a new key-value pair and adds it to the hash table. Notice that the specific hash index is already computed for you. Follow the instructions in the code. - Write the
get()function, which searches the hash table for a specific key and returns the corresponding value. - At this point you can test get/put using
HashtableMapTester.java. The only part you’ll need to write extra test code for is for whenputhas to overwrite a value with a new value (when youputthe same key twice with different values). - Write
containsKey(). This is almost identical toget; in fact you can write this in terms of get if you want. Test inHashtableMapTester. - Write
size(). Follow the instructions in the code. Test inHashtableMapTester. - Write
keySet(). Follow the instructions in the code. Test inHashtableMapTester. - Write
printTable(). This is the hardest function to get right, though it’s not particularly complicated in how it works. Follow the instructions in the code. Test inHashtableMapTester.
✅✅✅ At this point your HashtableMapTester output should match mine. Compare it.
Part C: Reading the file
Next, you will write code in AutocorrectDemo.java to open a file with a large amount of text and tally up how often each word occurs. You have two sample files: small.txt, which is a small demo file, and nyt.txt, which is a large amount of text taken from New York Times articles.
- Fill in the code in
processFile()to read in the text and keep a count of each word frequency. The way this code works is almost identical to how you processed the text in the movie reviews program (except there are no scores). Loop over the words in each line, and keep track of the number of times you see each word inwordFreqs. - When done, you should be able to run
main()in AutocorrectDemo. Compare your output onsmall.txtandnyt.txtagainst mine. It should match up to theprintTablestep. Note that in order to match, you should use a table size of 5 withsmall.txtand a table size of 23456 withnyt.txt.
Part D: Writing the autocorrector
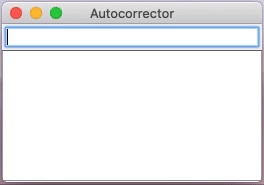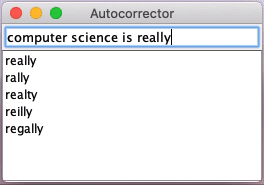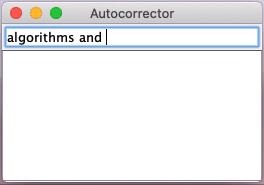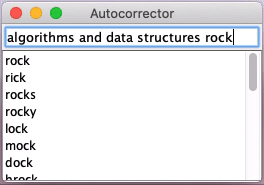
In the last step, you will write the code for the autocorrector. When you are typing on your phone, your phone tries to predict what you’re typing in two different ways.
- First, it tries to autocomplete what you’ve typed, in that it assumes what you’ve typed is the beginning of a longer word, and it tries to predict the remaining letters in the word.
- Second, it tries to autocorrect what you’ve typed, in that it tries to figure out if you made a spelling mistake while typing, and it tries to predict what you actually meant.
In part D, you will write code for both of these tasks.
✅✅✅ Sample output for small.txt, nyt.txt.
Begin in
getBestAutocompletein Autocorrector.java. Write this function, which is designed to take a string and look for the most common word in the wordFreq map that has the string as a prefix (this is the “autocomplete” part of the autocorrector: it’s going to predict what word you’ve typed the first few letters of).- To write this function, loop over all the words in the
wordFreqmap using keySet(). For each word, see if inputString is a prefix of that word. If so, then get the word’s frequency, and find the largest frequency. (This sounds complicated, but it’s just the standard maximum algorithm you learned in 141.) - If there are no strings in the
wordFreqmap with the inputString as a prefix, you should returnnull.
- To write this function, loop over all the words in the
- Once you’ve written
getBestAutocomplete, you can start running the test code intestAutocorrect(). At this point, only the “Autocomplete” lines will work, but you can test your output against mine, for bothsmall.txtandnyt.txt. - The autocorrect code is already written for you. This code (in
editDistance1andgetBestAutocorrect) takes a string that the user has typed in and looks for all strings in yourwordFreqmap that have only one letter difference, where a difference can be a letter substitution, transposition, or adding or removing one letter. So for instance, if you typed inct, it would find words likecat,cot,at, etc. Now you can write
getBestSuggestions(). You will write this function in two phases. For now, what you should inside this function is:- Call
getBestAutocompleteandgetBestAutocorrectand store the results in variables. - Make a new ArrayList of strings to hold the final result.
- Add all the strings that came back from
getBestAutocorrect(this is a set) to the ArrayList. - If the autocomplete string is not null (it might be null), then add it to the ArrayList as well.
- return the ArrayList as the return value of the function.
- Call
- You’re almost done! At this point you can run the tester code on both small.txt and nyt.txt, and the only difference should be the order of the words that come out of
getBestSuggestions. If you want to have some fun, try testing out the graphical user interface by uncommenting the two lines at the end ofmain(). - Last step: We need to sort the autocomplete/autocorrect suggestions by word frequency. To do this, we will write a
Comparator<String>(I promised we’d come back to those!). Head back toAutocorrecter.java. At the very end is aComparatorfor Strings. You must fill in thecomparefunction to do a two-level comparison between the Strings s1 and s2, which will be words from yourwordFreqmap. The basic idea is to compare s1 and s2 by their corresponding values in the map (which are, of course, how often each word appeared in the original text file.) s1 should come “before” s2 if s1 is a more popular word (has a higher frequency) than s2.- Here’s how to do it:
- Get the frequency of each word (s1 and s2).
- If the frequencies are different, return either -1 or +1 depending on which frequency is higher (think about which goes with which).
- If the frequencies are the same, then we will compare the strings based on alphabetical order, whicih you can do by calling
s1.compareTo(s2)and returning the result.
- After you write the
Comparator, you must call your quicksort function from earlier. - Inside
getBestSuggestions(), after you’ve added all the strings to a new ArrayList, you should do the following:
WordByFrequencyComparator comp = new WordByFrequencyComparator();
Quicksort.quicksort([name of your list variable], comp);
Then return the list of strings, and you’re done! Your output should match mine now.
Part E: Celebrate
At this point, you are done! You should confirm that your output matches mine exactly on small.txt and nyt.txt. The only parts that might be different are the results printed from “Autocorrect”, but the results from “Autocomplete” and “Best suggestions” should match exactly.
Feel free to play around with the GUI.
Testing your code
Look for the green check marks above, and make sure your output matches mine for those tests.
At the end of the project
- As you are preparing to submit the project, please prepare a text file (
.txt, pdf, or Word doc is fine) answering the following questions:- What bugs and conceptual difficulties did you encounter? How did you overcome them? What did you learn?
- Describe whatever help (if any) that you received. Don’t include readings, lectures, and exercises, but do include any help from other sources, such as websites or people (including classmates and friends) and attribute them by name.
- Describe any serious problems you encountered while writing the program.
- Did you do any of the challenges (see below)? If so, explain what you did.
- List any other feedback you have. Feel free to provide any feedback on how much you learned from doing the assignment, and whether you enjoyed doing it.
- Please also add a comment at the top of your program stating your name and a pledge that you have followed the honor code and collaboration policy for this project. This can be as simple as writing “I have neither given nor received unauthorized aid on this program.” You can find the collaboration policy on the syllabus.
- Remember, projects will be graded not only on correctness, but also appropriateness and efficiency of the algorithms you choose, and on coding style.
Submitting your code
Please, please, please before submitting, make sure that in AutocorrectDemo.java, the call to testAutoCorrect is uncommented (because I will run this function to test your code). It would also be helpful if you commented out the two calls to the window code that opens the GUI (since I will not use that to test your code).
Upload all the Java files to Canvas; there are 7 in total:
- AutocorrectDemo.java
- AutocorrectFrame.java (you will not have changed this file)
- Autocorrector.java
- HashtableMap.java
- HashtableMapTester.java (you may or may not have changed this file)
- Quicksort.java
- QuicksortTester.java (you may or may not have changed this file)
Hints and tips
- The
get()&put()functions in the hash table should not iterate over the entire table. The whole point of a hash table is you get constant time access to the correct slot in the table, calculated from the hash function. So the first thing you should do inside get & put is determine the correct index in the table to examine (and you’ll never need to look at any other index, because we’re using chaining). Note thatputalready has this written for you; you can use the same idea inget.- Note that
getandputare allowed to iterate over the linked list at the appropriate index.
- Note that
- On the other hand,
printTableandkeySetwill need to iterate over the entire hash table.